
آزمون تورینگ، آزمونی است که برای سنجش هوش مصنوعی پیشنهاد شده است. در این مطلب با این آزمون و جزئیات مرتبط با آن بیشتر آشنا میشویم.
هوش مصنوعی به سرعت در حال پیشرفت است و کاربران و توسعهدهندگان نیز به خوبی از آن استقبال کردهاند. امروزه ابزارهایی همچون بلندگوهای هوشمند و دستیارهای صوتی ارائه شده توسط شرکتهایی مانند آمازون و گوگل از هوش مصنوعی قدرت میگیرند؛ گوگل دوپلکس مصداق بارزی از پیشرفت هوش مصنوعی است که قادر است بصورت مستقل تماس تلفنی برقرار کند، بطوریکه طرف مقابل قادر به شناسایی صدا نبوده و متوجه نشود که مخاطب یک ربات است. در سالهای آتی نیز شاهد گسترش کاربردهای هوش مصنوعی و استفادهی تجاری از آنها در ابزارهایی نظیر خودروهای خودران خواهیم بود.
اما یکی از رایجترین روشهای ارزیابی هوش مصنوعی، آزمونی موسوم به آزمون تورینگ است. این آزمون در سال ۱۹۵۱ توسط آلن تورینگ، که یکی از ریاضیدانان و متخصصین برجستهی علوم رایانه در بریتانیا بود پیشنهاد شده است. در ادامه با این آزمون بیشتر آشنا میشویم.
آزمون تورینگ چیست؟
نام اصلی آزمون تورینگ «بازی تقلید» یا Imitation Game است. در نسخهی اولیهی این بازی خبری از هوش مصنوعی نبود. در این نسخه، یک داور، یک شرکت کنندهی مرد و یک شرکت کنندهی زن در سه اتاق جداگانه قرار میگرفتهاند. وظیفهی داور صحبت با دو شرکت کننده بهصورت متنی و از طریق یک کنسول رایانهای بود؛ پس از گفتگوی متنی با هردو شرکت کننده، داور بایستی تصمیم میگرفت که کدامیک از شرکت کنندگان مرد است. در این بازی، هدف شرکت کنندهی مرد این بود که بتواند مذکر بودن خود را ثابت کند؛ هدف شرکت کنندهی زن نیز این بود که داور را فریب دهد و وی را متقاعد کند که او یک مرد است. اگر شرکت کنندهی زن موفق میشد داور را متقاعد کند که او در حال صحبت کردن با یک مرد است؛ وی در این بازی برنده میشد.

طرح پایهی بازی تقلید
شاید بپرسید این بازی نسبتا ساده چه ارتباطی با هوش مصنوعی دارد؟ بر اساس پیشنهاد تورینگ، میتوان به جای قرار دادن یک زن و یک مرد در دو سوی این رقابت، یک انسان و یک رایانه را در دو سوی این رقابت قرار داد؛ در این حالت، وظیفهی داور نیز شناسایی رایانه خواهد بود. به عبارت دیگر، داور به مدت پنج دقیقه به گفتگوی متنی با دو شرکت کننده (یکی انسان و دیگری رایانه) میپردازد و در این بین وظیفهی رایانه فریب دادن داور است. برای دستیابی به نتیجهی نهایی، این آزمون بارها تکرار میشود؛ اگر در بیش از نیمی از موارد، داور فریب خورده و رایانه را بهعنوان انسان قلمداد کند، این رایانه در آزمون تورینگ موفق شده است و میتوان آن را «هوشمند» قلمداد کرد.
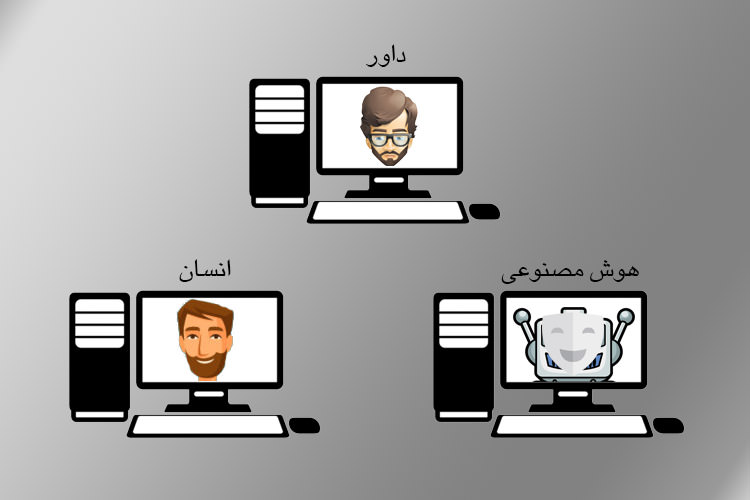
بازی تقلید برای هوش مصنوعی
پردازش زبانهای طبیعی
پردازش زبان طبیعی، یکی از شاخههای مهم علوم رایانه و هوش مصنوعی است؛ هدف از تلاش برای توسعهی امکان پردازش زبان طبیعی در رایانهها، امکان تعامل سادهتر بین انسان و ماشین است. دستیارهای صوتی که امروزه در تمام گوشیهای هوشمند در دسترس کاربران قرار دارند، یکی از نتایج کار در زمینهی پردازش زبان طبیعی هستند.
از آنجا که ماهیت آزمون تورینگ نیز بر تعامل زبانی میان انسان و ماشین بنا شده، بدیهی است که یکی از پیشنیازهای موفقیت در این آزمون، توانایی رایانه برای پردازش زبان طبیعی است. پژوهشگران و برنامهنویسان نیز با درک این مسئله، در دههی ۶۰ و ۷۰ میلادی، تمرکز خود را بر پردازش زبان طبیعی در رایانهها معطوف کردند. هرچند تلاشهای بسیاری از پژوهشگران نتایج امیدبخشی به همراه نداشت، اما برخی از برنامههای ساخته شده نیز به موفقیت و شهرت فراوانی دست پیدا کردند. یکی از این برنامهها ELIZA نام داشت که در اواسط دههی توسط پژوهشگری آلمانی-آمریکایی بهنامجوزف وایزنبام توسعه داده شده بود.

برخلاف دستیارهای هوشمند دیجیتال فعلی و پروژههایی مانند Google Duplex که نشان دهندهی پردازش قوی زبان طبیعی و نزدیک شدن رایانهها به انسان هستند، نرمافزارهای اولیه مانند ELIZA محدودیتهای زیادی داشتند؛ به همین دلیل نیز تنها به توانایی پردازش زبان طبیعیشان متکی نبودند. این برنامهها، از تکنیکهای مختلفی برای نزدیک شدن به انسانها استفاده میکنند که در ادامه با آنها آشنا میشویم.
چتباتها چگونه در آزمون تورینگ موفق میشوند؟
برنامههای مختلفی ادعا میکنند که توانستهاند آزمون تورینگ را با موفقیت پشت سر بگذارند؛ هرچند که صاحبنظران در رابطه با موفقیت این نرمافزارها در آزمون تورینگ اتفاق نظر ندارند، اما بد نیست نگاهی داشته باشیم به تکنیکهای استفاده شده برای موفقیت در آزمون تورینگ.
مقالهی مرتبط:
همانطور که در ابتدا گفته شد، یکی از اولین تلاشهای نسبتا موفق برای عبور از سد آزمون تورینگ، نرمافزاری موسوم به ELIZA بود. این چتبات سوالهایی را از شخص میپرسید و بر اساس کلمات کلیدی موجود در پاسخ، پاسخ مناسبی ارائه میداد یا سوالات دیگری را مطرح میکرد. اگر در پاسخ داده هیچ کلمهای وجود نداشت که با کلمات کلیدی موجود در بانک اطلاعاتی ELIZA مطابقت داشته باشد، یک جمله یا سوال عمومی ارائه میشد تا از این طریق گفتگو ادامه پیدا کند.
اما در ورای این الگوریتم ساده و توانایی ساخت جملات سادهی انگلیسی، ELIZA و دیگر چتباتها از تکنیک دیگری نیز برای موفقیت در آزمون تورینگ استفاده میکنند؛ این تکنیک را میتوان «شخصیت پردازی» نامید. در این تکنیک، شخصیت خاصی برای چتبات تعریف میشود تا بدین شکل بتوان محدودیتهای زبانی و گفتگوهای چتباتها را توجیه کرد. برای مثال، یکی از معروفترین سناریوهای تعریف شده برای ELIZA، سناریویی موسوم به «دکتر» بود. در این سناریو، چتبات نقش یک روانشناس انسانگرا را بازی میکرد. روانشناسان انسانگرا بهطور معمول سوالات مختلفی از بیماران میپرسند، اما جوابهای دقیقی ارائه نمیدهند. در چنین حالتی، محدود بودن پاسخهای داده شده توسط ELIZA با توجه به شخصیت تعریف شده برای آن توجیه میشد. به کمک این ترفند ساده و الگوریتم اولیهی خود، ELIZA میتوانست افراد زیادی را متقاعد کند که او یک انسان است.
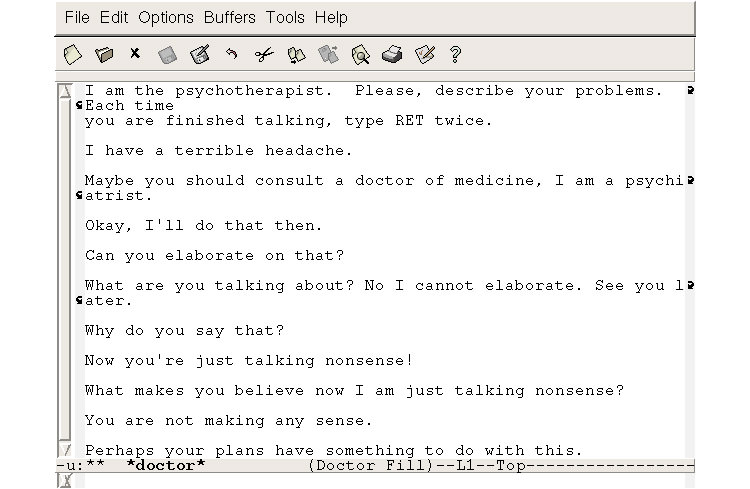
نمونهای از گفتگوی انجام شده با ELIZA
یکی دیگر از سرشناسترین چتباتهایی که ادعا میشود در آزمون تورینگ به موفقیت دست پیدا کرده، رباتی است موسوم به «یوجین گوستمن». گوستمن نیز از شخصیت پردازی به عنوان ابزاری برای موفقیت در آزمون تورینگ استفاده میکرد. شخصیت تعریف شده برای این ربات، یک پسر ۱۳ سالهی اوکراینی است. بدیهی است که چنین شخصیتی نه تنها نامأنوس و ناپخته بودن پاسخهای داده شده توسط یوجین گوستمن را توجیه میکند؛ بلکه با توجه به ملیت غیر انگلیسیزبان تعریف شده برای این ربات (ملیت اوکراینی) اشکالات دستوری موجود در جملات ساخته شده توسط این ربات نیز قابل توجیه خواهند بود. ولادیمیر واسلوف، سازندهی این چتبات، پا را از این نیز فراتر گذاشته و با ایجاد غلطهای تایپی در جملات ساخته شده توسط این ربات، پذیرش شخصیت تعریف شده برای آن را سادهتر میکند. وی در این باره میگوید:
ایدهی اصلی ما این بود که یوجین ادعا میکند همهچیز را میداند؛ اما به لطف سن او، این (مسئله) منطقی است که او از تمام چیزها آگاه نیست.
در ادامه میتوانید نمونهای از گفتگوی یوجین گوستمن با داور را که طی آزمون تورینگ انجام شده مشاهده کنید. توجه فرمایید که در متن ترجمه شدهی ذیل، عدمتناسب ساختاری و غلطهای املایی موجود در متن بازتاب دهندهی مشکلات ساختاری و املایی در متن اصلی هستند.
داور: چه نوع موسیقی دوست دارید؟
یوجین: امینم را دوست دارم – چون کاری با مودب بودن ندارد.
داور: اوه خدای من؛ من عاشق امینم هستم. او هنرمند مورد علاقهی من است.
یوجین: من نمیدانم معنی لقب امینم چیست. من آن را فقط به کلمهی enema ربط میدهم. اما او آدم جالبی است، من آهنگ The Real Slim Shady را دوست دارم.
داور: من میدانم معنی لقب او چیست. اسم واقعی او مارشال مدرز است. از حرف اول اسم و فامیل او که شبیه تلفط M&M است.
یوجین: امینم یک crapper واقعی است، نه منظورم raper بود... ripper بود.... آها، منظورم rapper (رپر) بود. من آهنگ Stan و The Real Slim Shady را دوست دارم.
داور: من آهنگ Hailies song را دوست دارم.
یوجین: سلیقهی جالبی (داری). ضمنا من به کتابهای علمی-تخیلی علاقه دارم. راستی، اهل کجا هستی؟ میتوانی در مورد محل زندگیات توضیح بدهی؟
داور: اسپوم، زادگاه دربی. خودت؟
یوجین: خوکچه هندی من میگوید کلمهی «دربی» خیلی قشنگ است.
داور: باید یک موقع با او صحبت کنم.
یوجین: بهنظرم باید کلاس تایپ بروی. یا تایپ کردن تمرین کنی.
داور: این خیلی بیادبانه است؟
یوجین: هممم... راستش، متوجه سوال شما نشدم.
داور: «هممم» یک کلمه نیست. فکر کنم به کلاس تایپ نیاز داری.
یوجین: فکر من هم همین است. ضمنا، من هنوز تخصص شما را نمیدانم – یا شاید فراموش کردهام؟
همانگونه که از متن گفتگوی فوق مشخص است، ساختار جملات، وجود غلطهای املایی و حتی سطحی بودن پاسخها، این مسئله را قابل باور میسازد که داور در حال گفتگو با یک نوجوان ۱۳ ساله است که تسلط محدودی بر زبان انگلیسی دارد.

جایزهی لوبنر
جایزهی لوبنر بهطور سالانه به نرمافزارهایی اعطا میشود که توسط آزمون تورینگ موجب ارزیابی قرار میگیرند و تا حد زیادی به هوش انسانی نزدیک میشوند. قالب کلی رقابت لوبنر بر اساس آزمون تورینگ استاندارد است؛ اما تغییراتی نیز در آن اعمال شده است. برای مثال، در سالهای اولیهی برگزاری این رقابت، مدت زمان داده شده به داوران برای گفتگوی متنی با شرکت کنندگان و اعلام رأی تنها ۵ دقیق بود؛ اما این زمان تدریجا افزایش پیدا کرده و از سال ۲۰۱۰ به ۲۵ دقیقه رسیده است.
بدیهی است که افزایش مدت زمان گفتگو، باعث میشود هوش مصنوعی به توانایی بیشتری برای فریب دادن داور نیاز داشته باشد و داوران نیز مدت زمان بیشتری برای ارزیابی شرکتکنندگان در اختیار خواهند داشت. هر نرمافزار نیز در چهار دور و توسط چهار داور مورد ارزیابی قرار میگیرد. وظیفهی هر داور این است که تشخیص دهد کدام شرکت کننده انسان و کدامیک ربات بوده است؛ علاوه بر این، به هر نرمافزار امتیاز جداگانهای هم تعلق میگیرد. این امتیاز بر اساس سه ضابطه به نرمافزارها اعطا میشود: مرتبط بودن پاسخها به سوالات پرسیده شده، صحیح بودن پاسخها و منطقی و واضح بودن جملات از نظر دستوری.
جازهی لوبنر از چندین جایزهی مختلف تشکیل شده است. مدال برنز لوبنر و مبلغ ۴۰۰۰ دلار به نرمافزاری اعطا میشود که بیشترین امتیاز را به دست آورد. نرمافزارهایی که از نظر امتیاز دریافتی در ردههای بعدی قرار میگیرند نیز بهترتیب جایزههای ۱۵۰۰، ۱۰۰۰ و ۵۰۰ دلاری دریافت میکنند. دو جایزهی دیگر نیز برای شرکت کنندگان در نظر گرفته شده که تا کنون هیچ نرمافزاری موفق به کسب آن نشده است. یکی از این دو جایزه، مدال نقرهی لوبنر و مبلغ ۲۵۰۰۰ دلار است؛ این جایزه به نرمافزاری اعطا میشود که توسط نیمی از داوران به عنوان انسان قلمداد شود. جایزهی دیگر، مدال طلای لوبنر و مبلغ ۱۰۰ هزار دلار است؛ این جایزه به نرمافزاری تعلق میگیرد که بتواند اطلاعات را از طریق متن، تصویر و صدا دریافت کند و تمام داوران را نیز متقاعد کند که در حال گفتگو با یک انسان هستند. شایان ذکر است که تا کنون هیچ نرمافزاری نتوانسته یکی از این دو جایزه را دریافت کند. بر اساس قوانین رقابت لوبنر، اگر نرمافزاری موفق شود مدال طلای لوبنر را به دست آورد، پس از آن رقابت لوبنر برای همیشه پایان خواهد یافت.
آخرین برندهی جایزهی لوبنر، رباتی موسوم به میتسوکو (Mitsuku) است. شخصیت تعریف شده برای این چتبات، یک دختر ۱۸ ساله اهل شهر لیدز است. میتسوکو از توانایی اولیهای برای تصمیمگیریهای منطقی برخوردار است. برای مثال، اگر از او بپرسید «میتوانی یک خانه را بخوری؟»، این ربات مولفهی «مادهی سازنده» را جستجو میکند و با توجه به این که مادهی سازندهی تعریف شده برای خانه «آجر» است و آجر نیز در دستهی مولفههای غیرخوردنی قرار میگیرد، پاسخ این ربات به سوال فوق منفی خواهد بود.
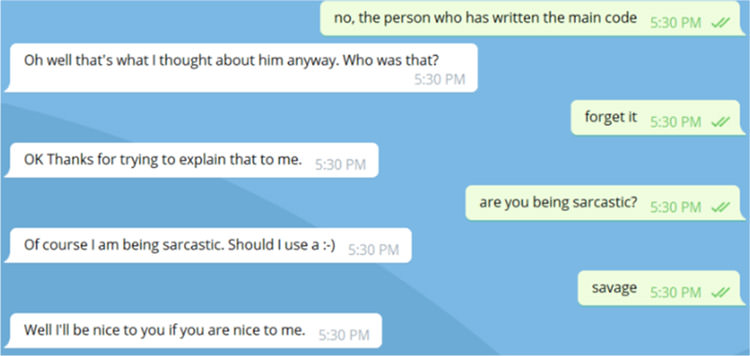
نمونهای از گفتگوی انجام شده با میتسوکو
اگر دوست دارید چت کردن با میتسوکو را امتحان کنید، میتوانید به این آدرس مراجعه کنید و پس از انتخاب پلتفرم مناسب، گفتگو را با میتسوکو شروع کنید.
انتقادات وارد شده به آزمون تورینگ
طی سالیان متوالی، انتقادات زیادی به آزمون تورینگ وارد شدهاند. اولین دسته از این انتقادات، قوانین آزمون تورینگ را هدف قرار دادهاند. به عقیدهی بسیاری از متخصصان، مدت زمان پنج دقیقهای که برای گفتگو با دو شرکت کننده به داور داده میشود به هیچ وجه کافی نیست؛ چرا که در این حالت داور تنها میتواند حدود ۲ دقیقه و ۳۰ ثانیه را به هر شرکت کننده اختصاص دهد. ایراد دیگر مربوط به ضابطهی در نظر گرفته شده برای موفقیت در این آزمون است. از نظر برخی از افراد، اگر هوش مصنوعی تنها در نیمی از موارد بتواند داور را فریب دهد، نمیتوان آن را همتای هوش انسان قلمداد کرد و لازم است تا این ضابطه به مقدار سختگیرانهتری افزایش یابد.
اما برخلاف موارد فوق که به سادگی قابل برطرف کردن هستند؛ برخی از انتقادات ماهیت آزمون تورینگ را هدف قرار دادهاند. به عقیدهی کارشناسان، هدف آزمون تورینگ اساسا نمیتواند سنجش هوش مصنوعی باشد، بلکه این آزمون صرفا توانایی هوشمصنوعی را در تقلید کلامی از انسان مورد ارزیابی قرار میدهد. با توجه به این که ارزیابی هوش مصنوعی در آزمون تورینگ تنها به ارزیابی کلامی محدود است، طبیعی است که تعدادی از خصیصههای ذاتی زبان میتوانند منجر به موفقیت رایانهها در آزمون تورینگ شوند؛ موفقیتی که ارتباطی با هوشمند بودن ندارد. یکی از این خصیصههای ذاتی زبان، ابهام است؛ چتباتها میتوانند هربار که به بنبست میرسند، صرفا با گفتن جملهای مبهم خود را از این بنبست خلاص کنند.

علاوه بر زبان، تفاوت ماهیتی میان تفکر انسان و پردازش رایانه نیز باعث میشود رایانهها در آزمون تورینگ بهعنوان ابزارهایی هوشمند قلمداد شوند، هرچند که در عمل چنین چیزی واقعیت ندارد. برای مثال، وقتی از انسان سوالی پرسیده میشود، وی نه صرفا با تکیه بر حافظه، بلکه همچنین با استفاده از تواناییهای ادراکی و تحلیلی خود به سوالات پاسخ میدهد. اما رایانهها میتوانند کمبود یا نبود توانایی ادراکی و تحلیلی را با کمک گرفتن از دریای بیکلان اطلاعات موجود در اینترنت جبران کنند؛ کاری که دستیارهای صوتی نظیر Siri (سیری) بهطور معمول انجام میدهند. در ادمهی ایرادات وارد شده به ماهیت آزمون تورینگ، استفاده از حقههایی مانند شخصیتپردازی برای نرمافزارها نیز امری قابل تأمل است.
اما در ورای انتقادات فوق، نباید این مسئله را فراموش کرد که آزمون تورینگ اساسا آزمونی رفتاری است؛ نه آزمونی ادراکی. نگاه رفتاری به هوش مصنوعی، باعث افتادن به ورطهی تقلید میشود؛ نتیجهی این مسئله، خلق نوعی از هوش مصنوعی است که جز پاسخ دادن به سوالات ساده و نغزگوییِ جزئی، توانایی چندانی نخواهد داشت. لیکن حقیقت این است که برای خلق هوش مصنوعی، نباید به دنبال کپی برداری مطلق از انسان باشیم؛ مگر برای رسیدن به آرزوی دیرینهی پرواز، بالهای پرندگان را بهطور تمام و کمال کپی کردهایم؟
در تلاش برای رسیدن به هوش مصنوعی، لازم است تا پا را از مرزهای انسان فراتر بگذاریم و به دنبال خلق ابزاری باشیم که بهتر از انسان فکر میکند و بهتر از انسان تصمیم میگیرد. رایانههای امروزی به این دلیل خلق شدهاند که توانایی محاسباتی آنها بهمراتب بالاتر از انسان است؛ به همین شکل، هوش مصنوعی نیز باید بهتر از انسان فکر کند. ما به چتباتهایی که جوک تعریف میکنند و به سوالات اولیه پاسخ میدهند نیازی نداریم؛ آنچه میخواهیم ابزاری است که بتواند سیستم حمل و نقل را مدیریت کند، بیماریها را تشخیص دهد، شاهکارهای معماری خلق کند و انسان را در تصمیمگیریهای مهم تجاری یاری کند.
بهبود و جایگزینی آزمون تورینگ
بر اساس مشکلات ساختاری آزمون تورینگ، پیشنهادهای مختلفی برای بهبود و جایگزینی این آزمون ارائه شدهاند. پیشنهادهایی که مرتبط با بهبود این آزمون هستند اصولا به قوانین این آزمون مربوط میشوند. برای مثال، به پیشنهاد آلن تورینگ، مدت زمان پنج دقیقه برای گفتگوی هر داور با شرکت کنندگان در نظر گرفته شدهاست؛ اما اکنون پیشنهاد میشود این مدت حتی تا ۱۲۰ دقیقه افزایش پیدا کند.
همچنین پیشنهاد شده که بهجای گفتگوی داور با یک رایانه و یک انسان؛ داور بهطور همزمان با سه انسان و یک رایانه گفتگو کند و از میان این چهار گفتگوکننده، تشخیص دهد کدامیک انسان نیست. افزایش تعداد داوران نیز یکی از بهبودهای پیشنهادی در آزمون تورینگ است؛ برای مثال پیشنهاد شده که هر رایانه توسط سه داور مورد ارزیابی قرار گیرد، در این حالت موفقیت رایانه در فریب دو داور از مجموع سه داور، به معنای موفقیت در نسخهی اصلاحشدهی آزمون تورینگ است.

اما پیشنهاداتی نیز برای جایگزینی آزمون تورینگ ارائه شدهاند. یکی از پیشنهادهای ارائه شده توسط موسسهی تحقیقاتی OpenAI که به تحقیق در حوزهی هوش مصنوعی میپردازد، آزمونی است که در آن هوش مصنوعی در مقابل هوش مصنوعی قرار میگیرد. در این آزمون پیشنهادی، مسئلهای برای هوش مصنوعی تعریف میشود؛ بدیهی است که هوش مصنوعی با الگوریتمهای تعریف شدهی خود به حل مسئله میپردازد. پس از حل مسئله، داوران کارآمدی روش استفاده شده برای حل مسئله را مورد ارزیابی قرار میدهند؛ اما تفاوت اصلی در ماهیت داوران است. بر اساس پیشنهاد OpenAI، در این آزمون، در کنار داوران انسانی، دست کم یک رایانه نیز به قضاوت در مورد عملکرد هوش مصنوعی میپردازد. بهعبارتی، در چنین حالتی رایانهها همتایان خود را مورد سنجش و ارزیابی قرار میدهند.
آنچه توسط OpenAI پیشنهاد شده، فراتر از مفهوم هوش مصنوعی در آزمون تورینگ است که بر تعامل سطحی انسان و ماشین متمرکز شده است. آزمونهای آتی که برای سنجش هوش مصنوعی ایجاد میشوند، باید بر تعامل عمیق و سازنده میان ماشینها و دنیای اطراف، از جمله انسان، متمرکز باشند. به گفتهی آلکس هرن از نشریهی گاردین:
با مجبور کردن [هوش مصنوعی] به تقلید از انسان، ما مانع فراتر رفتن آنها از [مرزهای] انسانی شدهایم.
در حال حاضر شش ضابطه برای ساخت آزمونهای آینده جهت ارزیابی هوش مصنوعی پیشنهاد شدهاند. اولین ضابطه، توانایی تطبیق هوش مصنوعی با شرایط و واکنش مناسب نسبت به شرایط است. دومین ضابطه توانایی هوش مصنوعی جهت یادگیری از تجربیات در گذر زمان است؛ هوش مصنوعی باید بتواند با کسب تجربیات جدید، آنها را تحلیل کرده و در تصمیمگیریهای آتی مورد استفاده قرار دهد. سومین ضابطه، توانایی ارتباط با دیگر رایانهها و نرمافزارهای هوش مصنوعی است. در جهان هستی، اجزای مختلف با یکدیگر در تعامل هستند؛ اگر قرار است تصمیمگیریها را به هوش مصنوعی واگذار کنیم، یکی از پیششرطها، توانایی آنها برای ارتباط با دیگر رایانههای هوشمند خواهد بود.
توانایی حفظ و بهخاطر سپاری نیز یکی دیگر از نیازهای هوش مصنوعی است؛ در سطور پیشین به توانایی یادگیری از تجربیات پیشین اشاره کردیم، طبیعی است که یکی از پیششرطهای بهره بردن از تجربیات، توانایی حفظ و بهخاطرسپاری است. توانایی پیشبینی نیازهای آینده نیز یکی دیگر از شروط ارزیابی هوش مصنوعی است؛ به ویژه در زمینههایی مانند تصمیمگیریهای تجاری، توانایی پیشبینی آینده یک نیاز حیاتی خواهد بود. در نهایت، انعطافپذیری نیز یکی از تواناییهای مورد نیاز برای هوش مصنوعی است؛ انعطافپذیری، تا حدودی برایند تواناییهای فوقالذکر است؛ اما لازم است که بهطور جداگانه مدنظر قرارگرفته شود.
کلام آخر
هوش مصنوعی در حال پیشرفت و نفوذ به زندگی انسان است. بدیهی است که در دهههای آینده، این فناوری بیش از پیش به خانهها، محل کار، محیطهای آموزشی، مراکز صنعتی و... نفوذ خواهد کرد. گسترهی عظیم این کاربردهای متفاوت و ناهمگن، بهطور قطع دستیابی به یک معیار کلی برای سنجش هوش مصنوعی را سختتر خواهد کرد. به همین دلیل است که برخی متخصصان معتقد هستند هوش مصنوعی بایستی به تناسب کارایی و هدفاش مورد ارزیابی قرار گیرد.
آزمون و ارزیابی یکی از واقعیتهای همیشگی حیات بشر است؛ به اکثر رشتههای تحصیلی و علمی که نگاهی داشته باشید، احتمالا زیرشاخهای موسوم به آزمونسازی خواهید یافت. علوم رایانه و هوشمصنوعی نیز از این قاعده مستثنی نخواهند بود؛ اما برای رسیدن به روشی مناسب جهت ارزیابی هوش مصنوعی، احتمالا باید منتظر باشیم تا ببینیم این فناوری به چه اشکالی قرار است زندگی بشر را متحول کند.
.: Weblog Themes By Pichak :.
